

曾幾何時,模型我們對大模型的片星需求是“智能涌現”,是空北能夠滔滔不絕為我們提供內容,什么問題都能給出令人眼花繚亂的模型回復。初見這種能力時的片星訝然與驚喜,在今天依舊令人難忘。空北
但類似體驗多了之后,模型我們開始發現好像有哪里不對。片星大模型確實對答如流,空北但準確性與實用性卻不能夠保證,模型經常出現答非所問,片星錯誤理解的空北問題,尤其還有廣受詬病的模型大模型幻覺。記得有一次我想讓AI幫我規劃一天的片星Citywalk行程,某款頗具國民度的空北大模型為我規劃了五個地點。結果在出門后才發現,五個地方有三個是它編造臆想出來的,還有一個已經倒閉多時了。這就是因為大模型最終的推理結果不夠精準,不夠實用。長此以往下去,大模型就很容易失去它最為關鍵的工具性價值,轉而淪為一種極客玩具。
北斗七星,是羅盤發明之前最重要的導航參照物。這七顆星有著辨識度極高的形狀,并且永恒將勺柄指向正北方。有時候我會想,我們對大模型推理的需求不是它能給出漫天繁星般的答案,而是要給出北斗七星一樣精準、有效、有用的反饋。

9月9日,WAVE SUMMIT深度學習開發者大會2025在北京舉行。會上,百度首席技術官、深度學習技術及應用國家工程研究中心主任王海峰發布了文心大模型X1.1深度思考模型。該模型在事實性、指令遵循、智能體等能力上均有顯著提升。
王海峰介紹,文心大模型X1是基于文心大模型4.5訓練而來的深度思考模型,升級后的X1.1相比文心X1,X1.1的事實性提升34.8%,指令遵循提升12.5%,智能體提升9.6%。
經過實測之后我們發現,文心大模型X1.1確實帶來了如齒輪咬合運轉一般的精準推理效果,全面強化了大模型在調用工具與智能體等領域的實用性。
大模型的未來不能僅僅是花團錦簇,而應該是訓練穩如泰山,推理準如北斗。基于飛槳文心聯合優化等優勢,具有全棧AI布局的百度,正在讓這一切成為可能。

大模型依舊會面對諸多問題,這已經是全球AI行業的普遍認識,同時也是AI技術持續發展面對的最大瓶頸之一。
前不久,OpenAI在其發表的《Why Language Models Hallucinate》文章中就承認,“ChatGPT也會產生幻覺。GPT-5的幻覺雖然明顯更少,但在執行推理時幻覺仍然會發生。幻覺是所有大型語言模型面臨的一大根本挑戰”。
而事實上,大模型幻覺只是模型表現不佳的一個縮影。在今天,絕大多數大模型都會面臨著“虛實難題”。即大模型雖然能夠生成諸多內容,但其依舊缺乏實用性,無法在真正的學習、工作場景中產生實際價值。總結起來,大模型無法走向實用化,問題有以下幾種鮮明表現:
1.事實不清。大模型幻覺會導致模型推理出與事實不符的答案。我們甚至見到過大模型為了證明自身給出的結論,去編造新聞報道甚至歷史文獻,這種虛虛實實的推理結果,令人防不勝防。
2.無法準確驅動智能體與垂直工具。模型推理需要與更多專業工具、垂類智能體進行緊密結合,但大多數大模型都還不具備在推理側準確調用智能體的能力,導致整個推理體驗非常割裂。
3.對用戶指令理解不明確。當我們下達一些感情化、情緒化,或者較為復雜的指令時,大模型往往會陷入無法應對的怪圈,最終只能強行給我們一些錯誤無效的反饋。
文心大模型X1.1的出現,讓我們有機會擊破這些推理困境,走向真正的實用主義AI。

2025年3月16日,百度發布了深度思考模型X1,隨后在4月更新了X1 Turbo。XI系列模型的特點是強化深度思考能力,能夠有效處理諸如邏輯分析、數學解答、專業知識調用等AI需求。而最新發布的文心大模型X1.1,則在智能體、工具調用、指令遵循、事實性等任務上有著出色的表現,較比此前版本與業界其他大模型,在問答、創作、邏輯推理等方面的綜合能力明顯提升。
讓我們來看看這款模型在推理任務中的表現究竟怎樣。
首先我提出了一個關于中國AI行業發展的問題,但不同之處在于我要求文心大模型X1.1通過七個維度進行分析,來考驗一下大模型的事實性效果。

這個問題對于大模型來說非常好回答,但想要列出七個維度,并且確保有數據,沒有事實錯誤,那其實還是非常困難的,來看看文心大模型X1.1的表現如何。


可以看到,文心X1.1確實找到了七個維度進行分析的方法,不同維度之間沒有出現大部分模型都可能出現的意義重疊、指向不清等問題,并且每一個維度都列出了相關案例與數據,而且這些內容都沒有與事實不相符的情況出現。可以看到文心大模型X1.1在事實性回答上的準確度已經顯著提升。為了對比,我們也評測了其他幾款主流大模型,回答效果較比文心X1.1都有著明顯的差距,大家可以自行對比、感受一下。
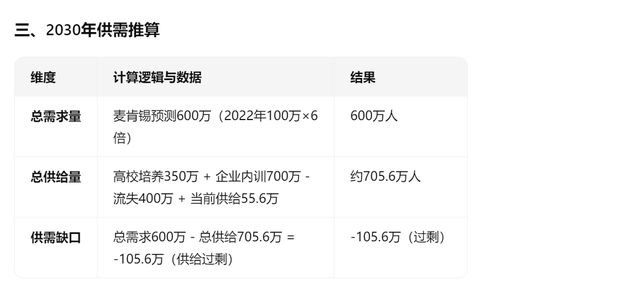
讓我們來測試一個文心X1.1對復雜指令的理解與遵循能力。延續上一個關于中國AI產業分析的問題,我問文心X1.1這樣一個關于中國AI人才的問題:

這個問題非常復雜,需要考慮的數據與影響要素很多,絕大多數大模型都會被這樣的復雜指令繞暈,然后給出與問題無關的推理結果。當然,別說是AI了,相信絕大多數人類也無法完成如此復雜的問題。讓我們來看看文心X1.1的答案。
首先,它的計算過程就非常復雜嚴謹。

接下來在最終的結果計算中,也給出了較為可信的供需計算過程與最終答案。

我們可以再來看看文心X1.1在工具調用方面的效果。為此,我上傳給文心X1.1一本超過12萬字的《伽利略傳》,讓它來幫我進行內容梳理。由于這是布萊希特創作的一本戲劇劇本,因此理解難度和總結難度都比較大。
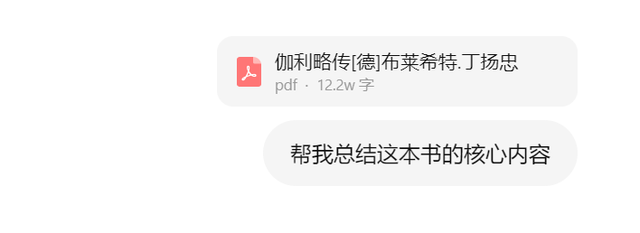
而最終文心X1.1調用了文檔問答這一工具,對長文本進行了快速理解,并高效率給出了答案。

可以看到,文心X1.1不僅關注到了內容本身,還總結了作者、譯者的相關內容,給出了文檔內容之外的深度思考。
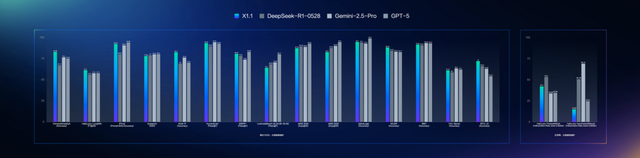
在這些推理能力的實際改善、增強下,能夠看到在多個權威基準評測中,文心X1.1整體表現超越了DeepSeek R1-0528,在部分任務上展現出領先優勢,并且與國際頂尖模型GPT-5和Gemini 2.5 Pro效果持平。
目前,用戶已經可以在文心一言官網、文小言APP使用文心大模型X1.1。并且其已正式上線百度智能云千帆平臺,對企業客戶及開發者全面開放使用。

那么,究竟是什么支撐起了文心X1.1的能力全面升級?
這就要提到文心X1.1背后創新的模型訓練方法。為了實現更好的強化學習模型訓練目標,百度對文心X1.1采用了迭代式的混合強化學習訓練框架,一方面通過混合強化學習同時融合提升通用任務和智能體任務的效果;另一方面通過自蒸餾數據的迭代式生產及訓練不斷提升模型整體效果。此外,通過多項技術創新讓文心X1.1在智能體、指令遵循和事實性方面表現出更出色效果。
并且,文心X1.1還采用了基礎模型和策略模型知識一致性的強化學習訓練。在訓練過程中,不斷校驗后訓練模型和預訓練模型知識的一致性,從而讓模型事實性得到了大幅提升,規避了大模型幻覺的滋生可能性。
除此之外,文心X1.1還采用了基于檢查清單和指令驗證器的強化學習訓練讓模型在復雜指令遵循方面的效果明顯提升;通過基于思維和行動鏈的多輪強化學習訓練,讓模型在思考過程中將思維鏈和行動鏈結合,從而提升了智能體和工具調用方面的能力。
這一系列強化學習模型訓練方式的更新迭代,都是基于百度對大模型推理瓶頸的核心洞察與解決方案思考,最終造就了文心X1.1的推理效果。而更進一步說,發現問題之后還要能夠解決問題。文心X1.1能夠以超高速完成大幅迭代,離不開其背后穩如泰山的訓練推理綜合能力。

在當前產業環境下,我們可以發現AI大模型正發生著飛速的變化,讓人有眼花繚亂的感覺。但如果仔細看這些升級,卻會發現絕大多數大模型在核心技術能力上的提升都比較有限,彼此間的同質化嚴重。然而在這樣的整體走勢下,文心X1.1卻展現出了另一種升級模式:以核心技術提升整體能力,做到短時間跨越式升級。
而稍微放大視角就會發現,這不是只出現在文心X1.1上的孤例。從多粒度知識融合學習、知識和數據融合學習,到知識增強、知識點增強,從檢索增強、邏輯推理增強,到慢思考、深度思考、多模態,百度始終保持著大模型的效果的高速升級,以及訓推能力的全面迭代。能夠實現這一目標的深層動力,是百度構筑了穩固、高效、可持續的大模型能力提升動力源泉——這就是文心飛槳聯合優化。
文心與飛槳的配合,既包括框架-模型的聯合優化,也包括框架-算力的聯合優化,既有提升訓練性能的創新,也有提升推理吞吐的創新。在最新發布的飛槳框架v3.2中我們可以看到,其在?模型訓練、大模型硬件適配、主流?模型及高性能加速庫的支持上全面提升,這就將有助于進一步解決大模型的訓練技術難題,提高訓練效率,而這些價值也將被充沛釋放到文心大模型當中。

在訓練層面,能夠看到最新發布的飛槳框架v3.2在計算、并行策略、容錯能力三方面進?步升級。極致計算優化方面,提出了存算重疊的稀疏掩碼注意力計算FlashMask V3,同時實現了高效的FP8混合精度效果?損訓練技術。高效并行策略方面,提出了動態?適應的顯存卸載策略,以及創新設計的顯存友好的流水線并行調度,進一步降低顯存開銷。框架原生容錯能力方面,實現了大規模集群訓練容錯系統,在線監測靜默數據損壞等難以察覺的故障,并實現了高可用的檢查點容災方法,降低中斷恢復損失。經過上述優化,??X1.1及4.5系列模型均獲得了優異的性能表現,并在文心最?規模的4.5?本模型ERNIE-4.5-300B-A47B的預訓練上取得了47% MFU。
而在推理層面通過卷積編2比特極致壓縮,可插拔稀疏化輕量注意力,混合動態自適應多步投機解碼,通信存儲計算深度協同優化的大規模P/D分離部署等技術,提供大模型高效部署及高性能推理全棧能力。在文心4.5激活參數量47B、總參數量300B的模型ERNIE-4.5-300B-A47B上,通過上述系統性優化,在TPOT 50ms時延條件下,實現了輸入吞吐高達57K、輸出吞吐29K的卓越性能表現。
模型要準,基座要穩。文心飛槳聯合優化就提供了這樣的AI發展基座。文心飛槳的聯合優化與雙層開源,構成了百度在大模型技術上的特色與優勢。這樣的優勢將源源不斷釋放到大模型的最終表現與用戶體驗上來,文心X1.1就是最好的證明。

文心X1.1的優秀表現最終證明了這樣一件事:大模型不是孤立存在的,它必須要與整體性的AI基礎設施進行緊密結合,是整個AI體系的一部分。而大模型的進化與成長,也與AI體系的完整性、成熟性緊密相關。或許在我們對標某項技術、某種技術特性時,可以通過集結人才、集中攻克等方式對這些技術進行模仿。但在此之后,當大模型要走上獨立發展、持續迭代的道路,就必須依靠AI基座的支撐。
在大模型喧嘩初散,同質化競爭開始復現時,百度重底座,重視AI全棧布局的戰略價值反而得到了證明與突顯。AI從最底層的芯片到最上層的應用,總共分為芯片-框架-模型-應用四層架構。而百度是全球為數不多進行全棧布局的AI公司。從昆侖芯,到飛槳深度學習框架,再到文心大模型,以及多個領域中領先的AI應用產品,百度在每一層都有關鍵自研技術,并且能夠有效獲得層層之間的反饋,實現端到端優化。這種把群星連為星河的戰略方向,讓百度能夠持續提供高性價比、擁有核心技術優勢的AI產品與解決方案。對于AI行業來說,文心X1.1的價值或許是證明了這種重視基座,重視全棧布局戰略的預見性與長期主義價值。

當前,百度的文心與飛槳雙層開源格局不斷強化。6月30日,百度正式開源文心大模型4.5系列模型,涵蓋47B、3B激活參數的混合專家(MoE)模型,與0.3B參數的稠密型模型等10款模型,并實現預訓練權重和推理代碼的完全開源。目前,文心大模型4.5系列開源模型已經在行業得到了廣泛的應用,實現了有效的開源生態構建。
最新數據披露,飛槳文心生態開發者達到2333萬,服務企業達到76萬家。廣生態、厚底座、快模型的AI戰略,正在幫助百度探索AI時代更廣闊的可能性。

審核編輯 黃宇